
Anthropic Settles Its Copyright Litigation—and Why That Was the Right Move
As well as what it means for the broader landscape of litigation.

Anthropic settled its class-action copyright litigation brought by a group of book authors. The terms were headline-grabbing: Anthropic agreed to pay $1.5 billion (!) to authors whose works were found to have been torrented, while committing to destroy the downloaded copies. Importantly, the deal left Anthropic’s existing models untouched—the company doesn’t have to retrain or delete them. In this post, I’ll explain why I think this was a good idea for Anthropic, despite the price tag, and what it might mean for the landscape of copyright+AI.
Settling was the right move
From a strategic perspective, Anthropic made the right call. It was barreling toward a trial where it had torrented hundreds of thousands of books for training. Even with a Bay Area jury pool, I’m not sure it would have won that case.
The post-trial penalties could have been existential, and that posture could investment into the company. Statutory damages can reach up to $150,000 per work (that comes out to ~$70 billion for the ~465,000 covered books), far exceeding the settlement amount. That said, had Anthropic lost at trial, Judge Alsup might have reduced the penalties to a not-so-existential number. Here’s a table of some of Judge Alsup’s past judgments:
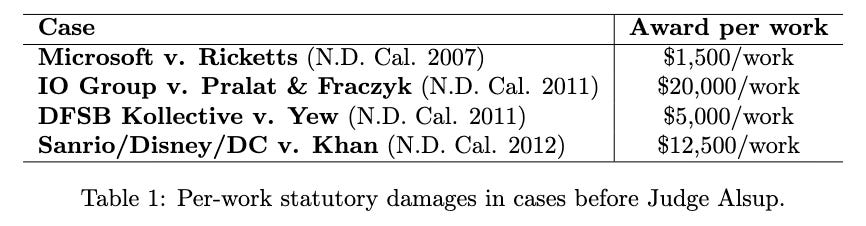
They’re often a bit more than the settlement amount, but still within the same ballpark. Anthropic was also blocked from appealing until after the jury trial concluded, meaning that if it lost, it would have had to appeal with an existential verdict hanging over it. That could have also affected later investment rounds.
Settling this way leaves a path to cheaper data acquisition. Crucially, it doesn’t require any changes to current models—and Anthropic can still use the books for training. It just has to buy a used copy and scan it.
Let me explain: Judge Alsup did rule in Anthropic’s favor on fair use ffor scanning books for training, while finding that torrenting was not fair use—albeit through somewhat roundabout reasoning. This means Anthropic was able to grow using torrented material, and now competitors are worse off because doing so is potentially riskier. At the same time, Anthropic has a ruling on the books that allows it to continue scanning used books for training. So Anthropic can pay the going rate for a single used book (likely less than $20 in bulk). As you can see, Anthropic’s decision to hire Google Books scanning guru Tom Turvey really paid off here.
(Aside: I’m not a fan of Judge Alsup’s split decision. To my mind it reflects a “good faith” factor that isn’t explicitly in the fair use statute. But my coauthors and I did correctly forecast that good faith would likely impact litigation—see here.)
Caveat 1: Anthropic may still need to fight off direct infringement claims for outputs of their models, which are not covered by the settlement. This means they need to continue to be vigilant on technical measures for preventing reproduced outputs or non-literal copying. We wrote how difficult this can be here.
Caveat 2: Judge Alsup rejected the settlement for now. His rejection flagged underspecified details: Who exactly would be covered? How would authors opt out? How would payments be distributed? So the deal is not yet finalized—what’s left to be done is hammering out the mechanics of class coverage, ensuring transparency in author compensation, and producing a settlement agreement that can withstand judicial scrutiny. As Judge Alsup stated, “We’ll see if I can hold my nose and approve it.” I expect that he will approve it—there are lots of incentives for the lawyers to smooth out the details, plaintiffs’ attorneys are set to get 25% of the settlement!
The Value of Books: $2,500 to authors?
One interesting thing about the settlement is the price tag. The number everyone keeps seizing on in the settlement—roughly $3,000 per work—didn’t come out of nowhere. In late 2024, HarperCollins quietly rolled out an opt‑in AI‑training license that paid $5,000 per title for three years, split 50/50 between the author and the publisher—so $2,500 to the author, $2,500 to HarperCollins—for use in training, fine‑tuning, and testing models. Looks similar to the current settlement numbers, after attorneys fees (estimated to be ~25%). Like the settlement the HarperCollins contract also did not grant derivative rights and authors did not disclaim output claims (i.e., if the model outputs the book verbatim, which could still trigger a lawsuit).
Other litigation and weaker cases.
I don’t think this settlement will cause the dominoes to fall in other cases necessarily. Some litigation, to my mind, has model creators in a stronger position—for example, mainly research-centric models (e.g., Nvidia, Databricks, Apple).
Going into this litigation, I thought Anthropic was in a fairly strong position. The main issue was the torrenting of books. The big question is whether the fair-use holding will extend to, say, scraping song lyrics from the web, as in Anthropic’s litigation with UMG and other music companies. In that case, UMG is suing over training Claude on lyrics. But there’s a key difference between the authors’ case and UMG: authors were not able to get Claude to reproduce books, whereas UMG was able to get Claude to reproduce lyrics. In my opinion, that puts Anthropic in a worse position in the UMG litigation. That being said, the courts are a bit all over the place with AI litigation, so I think we’ll end up with some incongruous decisions—leaving it to the Supreme Court to create more uniformity, or perhaps more chaos, soon enough.
The lawyers are the big winners.
I’ll leave you with this. This litigation is extremely expensive. Plaintiffs’ lawyers are about to receive 25-30% of $1.5B. So, the real winners are the lawyers. They will get a far bigger payday than the individual authors. I asked Gemini’s nano-banana model to help me come up with a cartoon here that I thought was fitting:

This is just going to incentivize plaintiffs’ side firms to keep bringing lawsuits. After all, why not? There is nothing, at this point, disincentivizing these lawsuits. Just the other day, Apple was sued for a research model (OpenElm) that uses the RedPajama dataset, which has part of the books3 corpus in it. Every single model training run, released model, and description of the underlying data risks bringing litigation. This is also not a great status quo for transparency. Firms are greatly disincentivized from revealing anything about their training process and from releasing model weights right now.
Who are we? Peter Henderson is an Assistant Professor at Princeton University with appointments in the Department of Computer Science and the School of Public & International Affairs, where he runs the Princeton Polaris Lab. Previously, Peter received a JD-PhD from Stanford University. Every once in a while, we round up news and research at the intersection of AI and law. Also, just in case: none of this is legal advice. The views expressed here are purely our own and are not those of any entity, organization, government, or other person.