
Quick Take: Are open-weight AI models really getting a fair shake in capabilities evals?
Thoughts on Anthropic's postmortem.

Anthropic recently wrote a postmortem on the increased rate of subpar model responses for Claude. It was really well done, showed the engineering depth of the folks on the team, and is (in my opinion) a model of information sharing that should continue to be made public. But I wanted to zoom in on one interesting tidbit from the post.
On August 5, some Sonnet 4 requests were misrouted to servers configured for the upcoming 1M token context window. This bug initially affected 0.8% of requests. On August 29, a routine load balancing change unintentionally increased the number of short-context requests routed to the 1M context servers. At the worst impacted hour on August 31, 16% of Sonnet 4 requests were affected.
Approximately 30% of Claude Code users who made requests during this period had at least one message routed to the wrong server type, resulting in degraded responses. On Amazon Bedrock, misrouted traffic peaked at 0.18% of all Sonnet 4 requests from August 12. Incorrect routing affected less than 0.0004% of requests on Google Cloud's Vertex AI between August 27 and September 16.
However, some users were affected more severely, as our routing is "sticky". This meant that once a request was served by the incorrect server, subsequent follow-ups were likely to be served by the same incorrect server.
Resolution: We fixed the routing logic to ensure short- and long-context requests were directed to the correct server pools. We deployed the fix on September 4. Rollout to our first-party platform and Google Cloud's Vertex AI was completed by September 16, and to AWS Bedrock by September 18.
Notably, this seems to imply that long-context requests are served by one model (or at least one configuration of a model), and short-context requests are served by another. Routing to the wrong model configuration will yield worse performance.
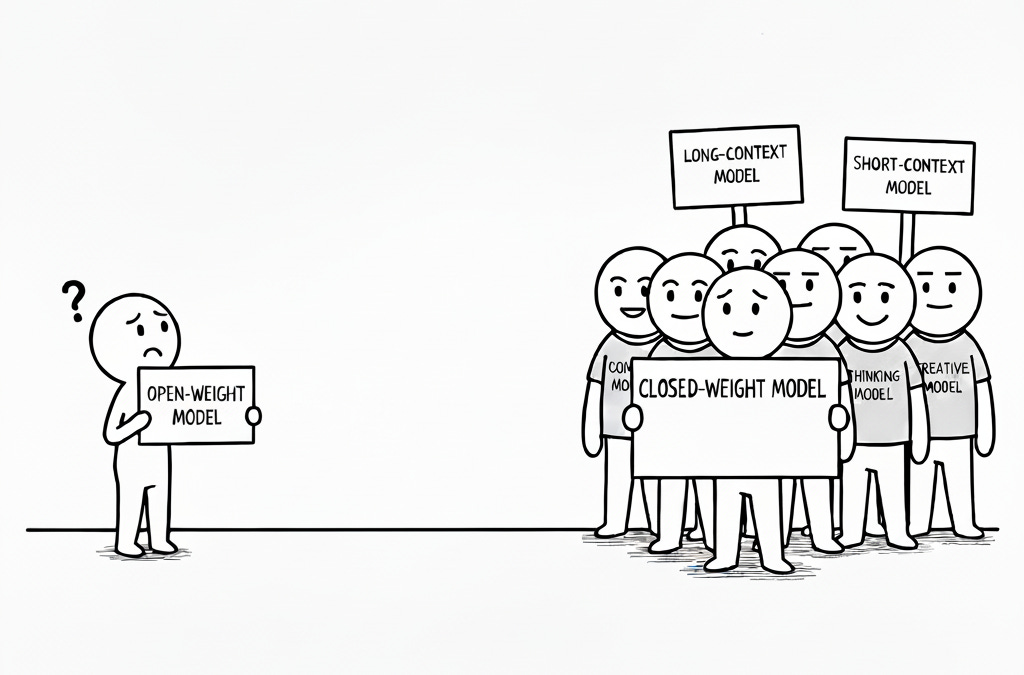
tldr; Closed models are actually systems of multiple models, but we compare them against single-artifact open-weight models. That’s not an apples-to-apples comparison. Are open models further ahead than we think?
GPT-5 is a router-based system, like Claude appears to be—sometimes routing to smaller models, sometimes thinking more, etc. In many ways, this seems like an unfair shake for open models. While closed models can rely on a suite of other models and systems, open-weight models must perform well in all conditions.
Then I wonder, from a capabilities perspective, whether the open-weight ecosystem is actually not as far behind the closed-weight ecosystem. If you allowed the same routing, specialization, and systems surrounding closed models, how much better could open models get?
Similarly, we don’t know whether there are any inference-time optimizations to boost performance of closed-weight models. Are they running something like best-of-n, majority vote, or other aggregation-based approaches for selecting an output? Are they doing MCTS? Maybe not, because these methods are expensive—but we just don’t know.
For research—and policy—purposes, maybe we should be leveraging systems around open-weight models and comparing system-to-system, not model-to-system. But, overall, I continue to hope that closed model providers give us metadata along with API calls so that researchers understand what exactly they’re comparing against

.
Great post and thoughts.
My personal view: GPT-5's routing pipeline seemed to meant mainly for reducing cost (as there seems a shortage of GPUs to satisfy users' high demands) and partially for enhancing inference speed for queries that do not require the most powerful models (to date) to solve. I doubt GPT-5 is doing MCTS (as that's quite expensive and would make inference slower) but I don't discard the possibility that OpenAI are doing sth more sophisticated than a single prompt for selecting an output. However, things like best-of-n or majority voting seem unlikely, as GPT-5 (and Claude ofc) outputs tokens synchronously/on real time. Similar arguments may be made for Claude, but as they experience a much smaller customer demand and thus probably have more spare GPUs for doing complicated model/output selections (e.g. routing to short- or long-context models depending on the input length).
On whether the open-weight ecosystem is actually not as far behind the closed-weight ecosystem (from a capabilities perspective): More work is needed to reliably verify this point and probably more metadata along with API from closed model providers would be essential to acquire certainty. My limited anecdotal evidence (with uncertainty due to the lack of knowledge about the system pipeline of closed models) seems to suggest that capabilities perhaps do not differ that much, but closed models seem noticeably better at things like instruction following, infer the actual intention of users, and alignment.